让TensorFlow飞一会儿
面对大型的深度神经网络训练工程,训练的时间非常重要。训练的时间长短依赖于计算处理器也就是GPU,然而单个GPU的计算能力有限,利用多个GPU进行分布式部署,同时完成一个训练任务是一个很好的办法。对于caffe来说,由于NCCL的存在,可以直接在slover中指定使用的GPU。然而对于Tensorflow,虽然Contrib库中有NCCL,但是我并没有找到相关的例子,所以,还是靠双手成就梦想。
原理简介
TensorFlow支持指定相应的设备来完成相应的操作,所以如何分配任务是很关键的一环。GPU擅长大量计算,所以整个Inference和梯度的计算就交给GPU来做,更新参数的小事情就交给CPU来做。这就比如校长要知道整个年级的平均成绩,就把改卷子的任务分配给每个班的老师,每个班的老师批改完卷子以后,把各自班级的成绩上交给校长,校长计算个平均数就行。在这里,校长就是CPU,每个班级的老师就是GPU。
下面放出一张图来说明问题。
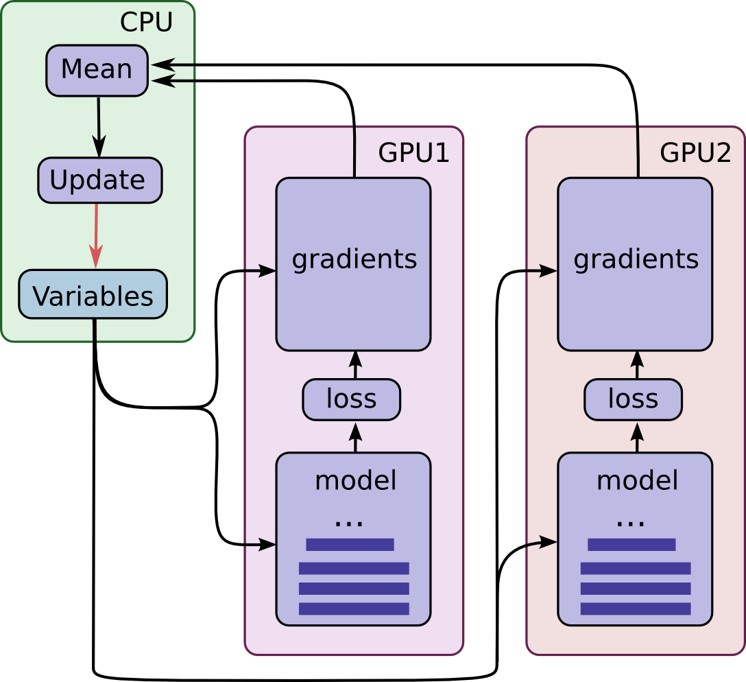
我们可以清楚的看到CPU中保存变量,GPU们计算整个model和gradients,然后把得到的梯度送回CPU中,CPU计算各个GPU送回来梯度的平均值作为本次step的梯度对参数进行更新。从图中我们可以看到只有当所有的GPU完成梯度计算以后,CPU才能求平均值,所以,整个神经网络的迭代速度将取决于最慢的一个GPU,这也就是同步更新。那能不能异步更新呢?当然是可以的把更新参数这个操作也放回到GPU上,但是异步更新会造成训练不稳定,有的快有的慢,你说到底听谁的…
在上图中我们可以看到有几个关键点需要注意:
- 在CPU上定义变量
- 在GPU上分别定义model和gradients操作,得到每个GPU中的梯度
- 又回到CPU中计算平均平均梯度,并进行参数更新
Talk is cheap, show me the code!!
好,下面放代码。
示例代码
示例代码分如下几个部分:
- 读入数据
- 在cpu中定义变量
- 搭建Inference
- 定义loss
- 定义训练过程
读入数据
由于是在不同的GPU上进行运算,所以我们采用TF官方的数据格式tfrecords作为输入,tfrecords的MNIST数据集格式可以在网上很轻易的找到。读入数据的时候我们就用标准的tfrecords数据集读入的格式。
1 | def read_and_decode(filename_queue): |
这段函数会返回一个图像和标签,我们需要按照Batch的方式读入
1 | def inputs(train, batch_size, num_epochs): |
到这里我们可以读入batch图像和标签。
在CPU中定义变量
我们需要把weight和biases定义在CPU中,以便进行参数的更新。注意1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16```Python
def _variable_on_cpu(name, shape, initializer):
"""Helper to create a Variable stored on CPU memory.
Args:
name: name of the variable
shape: list of ints
initializer: initializer for Variable
Returns:
Variable Tensor
"""
with tf.device('/cpu:0'):
dtype = tf.float32
var = tf.get_variable(name, shape, initializer=initializer, dtype=dtype)
return var
构建Inference
构建Inference采用的的是卷积神经网络的架构,需要注意的是初始化的时候需要将变量定义在CPU中。
1 | def inference(images): |
定义Loss
定义loss的时候和单GPU的形式不同,因为我们不仅要定义损失函数,还要定义每个GPU的损失函数值和其梯度,最后再计算平均梯度。
1 | def loss(logits, labels): |
定义训练过程
训练过程的需要注意把不同的环节放在不同的devices下面。
1 | def train(): |
最后就可以调用Train()函数进行训练了。训练函数分配GPU的时候有for循环,所以可以支持不同数量的GPU。
单机多卡服务器进行深度学习的训练,构建代码比较复杂,并且需要手动分配devices,相比于NCCL的高级库好的一点就是可以针对不同的任务进行定制化的分配,以实现最大程度的优化,工作量比较大,效果也非常好。搭建的时候需要平衡一下效率和开发速度。后续还会尝试多机多卡的情况,目前还在尝试。

